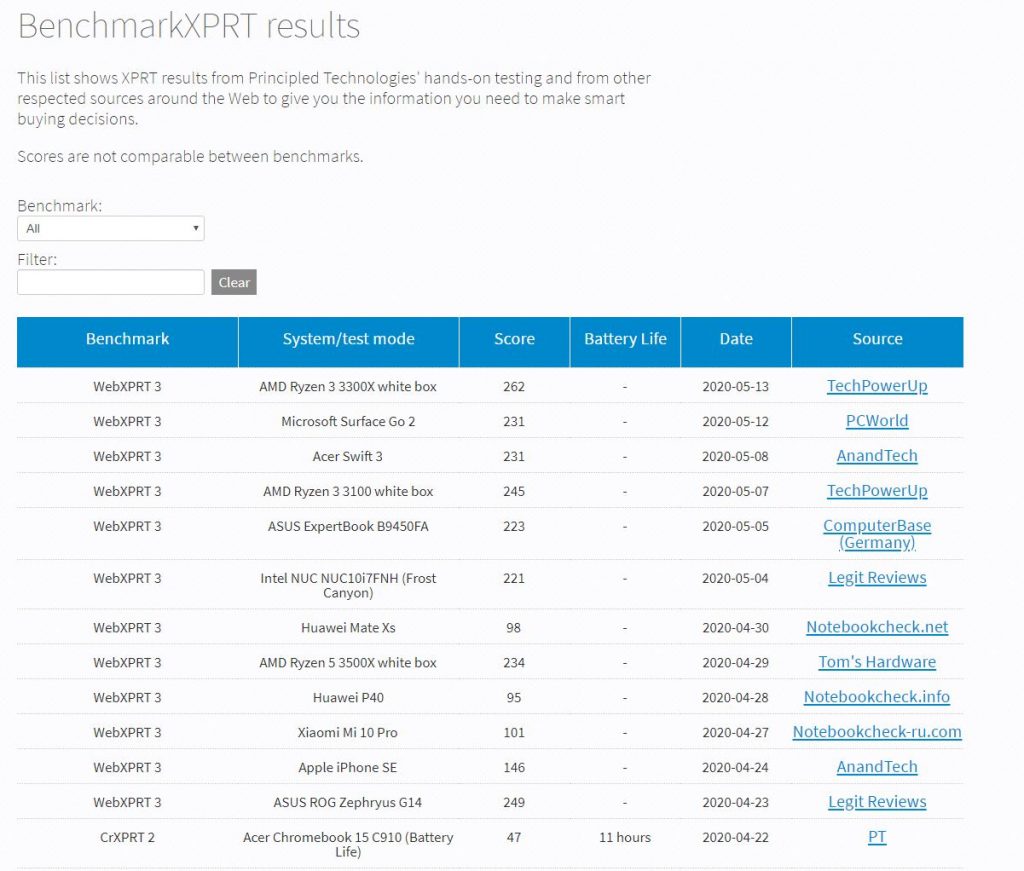
A few weeks ago, we discussed error messages that a tester received when starting up CrXPRT 2 after a battery life test. CrXPRT 2 battery life tests require a full battery rundown, after which the tester plugs in the Chromebook, turns it on, opens the CrXPRT 2 app, and sees the test results. In the reported cases, the tester opened the app after a battery life test that seemed successful, but saw “N/A” or “test error” messages instead of the results they expected.
During discussions about the end-of-test system environment, we realized that some testers might be unclear about how to tell that the battery has fully run down. During the system idle portion of CrXPRT 2 battery life test iterations, the Chromebook screen turns black and a small cursor appears somewhere on the screen to let testers know the test is still in progress. We believe that some testers, seeing the black screen but not the cursor, believe the system has shut down. Restarting CrXPRT 2 before the battery life test is complete could explain some of the “N/A” or “test error” messages users have reported.
If you see a black screen without a cursor, you can check to see whether the test is complete by looking for the small system power indicator light on the side or top of most Chromebooks. These are usually red, orange, or green, but if a light of any color is lit, the test is still underway. When the light goes out, the test has ended. You can plug the system in and power it on to see results.
Note that some Chromebooks provide low-battery warnings onscreen. During CrXPRT 2 battery life runs, testers should ignore these.
We hope this clears up any confusion about how to know when a CrXPRT 2 battery life test has ended. If you’ve received repeated “N/A” or “test error” messages during your CrXPRT 2 testing and the information above does not help, please let us know!
Justin