
We’re happy to announce that the CloudXPRT learning tool is now live! We designed the tool to serve as an information hub for common CloudXPRT topics and questions, and to help tech journalists, OEM lab engineers, and everyone who is interested in CloudXPRT find the answers they need as quickly as possible.
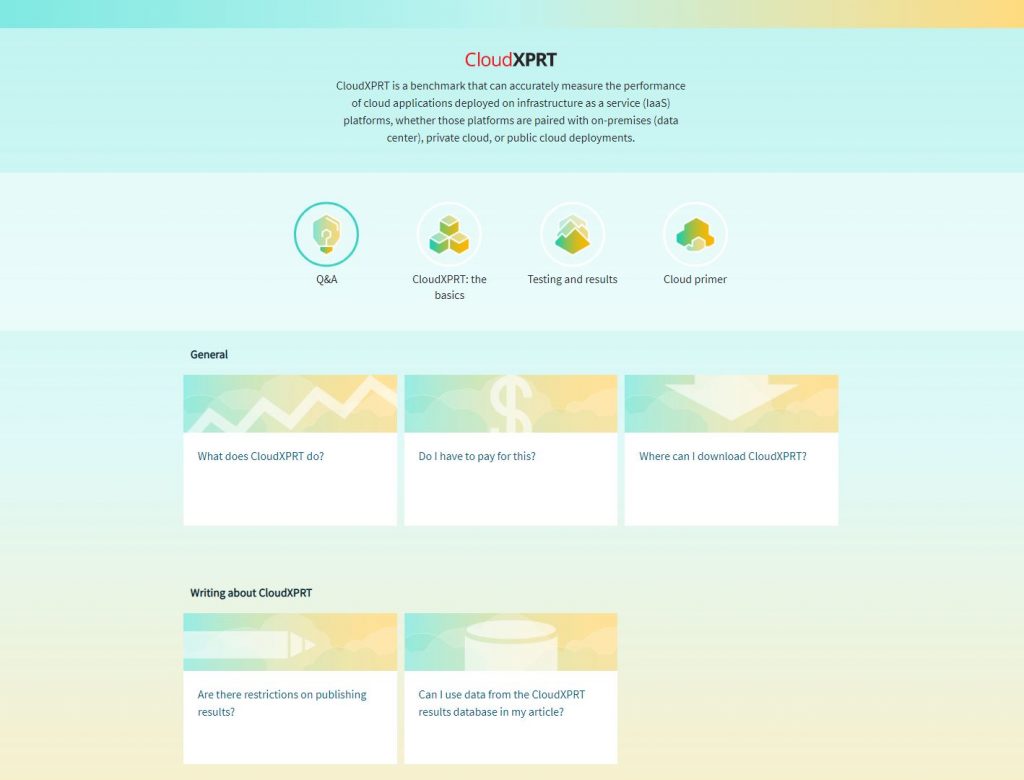
The tool features four primary areas of content:
- The Q&A section provides quick answers to the questions we receive most from testers and the tech press.
- The CloudXPRT: the basics section describes specific topics such as the benchmark’s target platforms, workloads, companion cloud software, and hardware and software requirements.
- The Testing and results section covers the testing process, metrics, and how to publish results.
- The cloud primer provides brief, easy-to-understand definitions of key cloud computing terms and concepts.
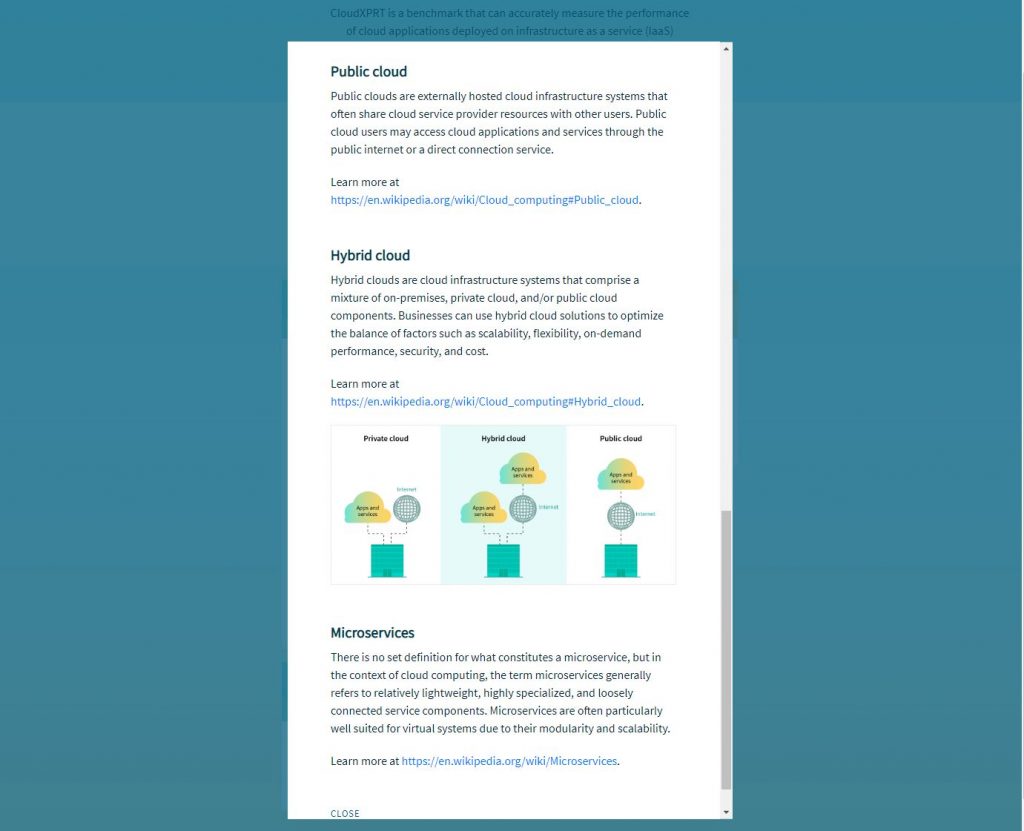
The first screenshot below shows the home screen. To illustrate how some of the pop-up information sections appear, the second screenshot shows part of the Key terms and concepts module in the Cloud primer section.
We’re excited about the new CloudXPRT learning tool! If you have any questions about the tool, or suggestions for additional content to include in it, please let us know!
Justin





