Happy 2019! January is already a busy time for the XPRTs, so we want to share a quick preview of what community members can expect in the coming months.
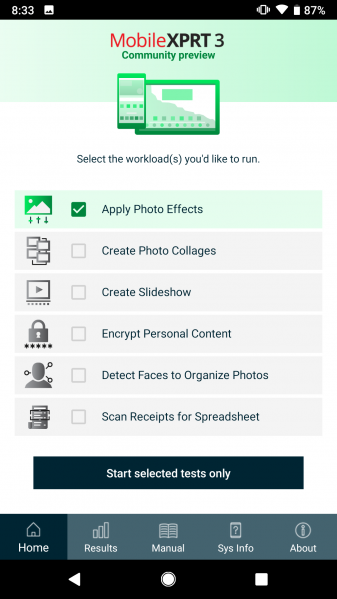
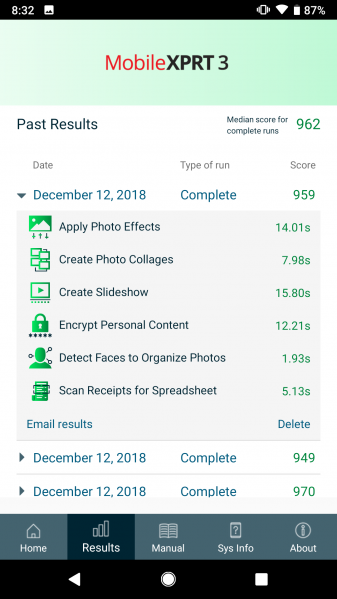
The MobileXPRT 3 community preview (CP) is still open, but draws to a close on January 18th. If you are not familiar with the updates and changes we implemented in the newest version of MobileXPRT, you can read more in the blog. Members can access this APK on the MobileXPRT tab in the Members’ Area. We also posted an installation guide that provides both a general overview of the app and detailed instructions for each step. The entire process takes about five minutes on most devices. If you haven’t already, give it a try!
We also recently published the first AIXPRT Request for Comments (RFC) preview build, an early version of one of the tools we’re developing to evaluate machine learning performance. You can find more details in Bill’s most recent blog post and on AIXPRT.com. Only BenchmarkXPRT Development Community members have access to our RFCs and the opportunity to provide feedback. However, because we’re seeking broad input from experts in this field, we’ll gladly make anyone interested in participating a member. To gain access to the AIXPRT repository, please send us a request.
Work on the HDXPRT 4 CP candidate build continues, and we hope to publish the preview for community members this month. We appreciate everyone’s patience as we work to get this right. We think it will be worth the wait.
On a general note, I’ll be travelling to CES 2019 in Las Vegas next week. CES is a great opportunity for us to survey emerging tech and industry trends, and I look forward to sharing my thoughts from the show. If you’ll be there and would like to discuss any aspect of the XPRTs in person, let me know.
Justin