Running AI inference workloads on the Stratus ztC Endurance 7100
There are countless critical real-world applications for classifying images using machine learning. AI image classification can help speed up quality assurance in industrial manufacturing by providing an automated method to prevent subpar products from making it to market. Accelerating this portion of the manufacturing process can ultimately get products on the shelf faster to meet customer demands. Quick inference for image classification can also lead to quick suggestions for customers shopping at online retailers, recommending other products based on the items they’ve shown interest in. No matter your specific image classification use case, choosing servers with strong throughput can help you get answers from your datasets more quickly.
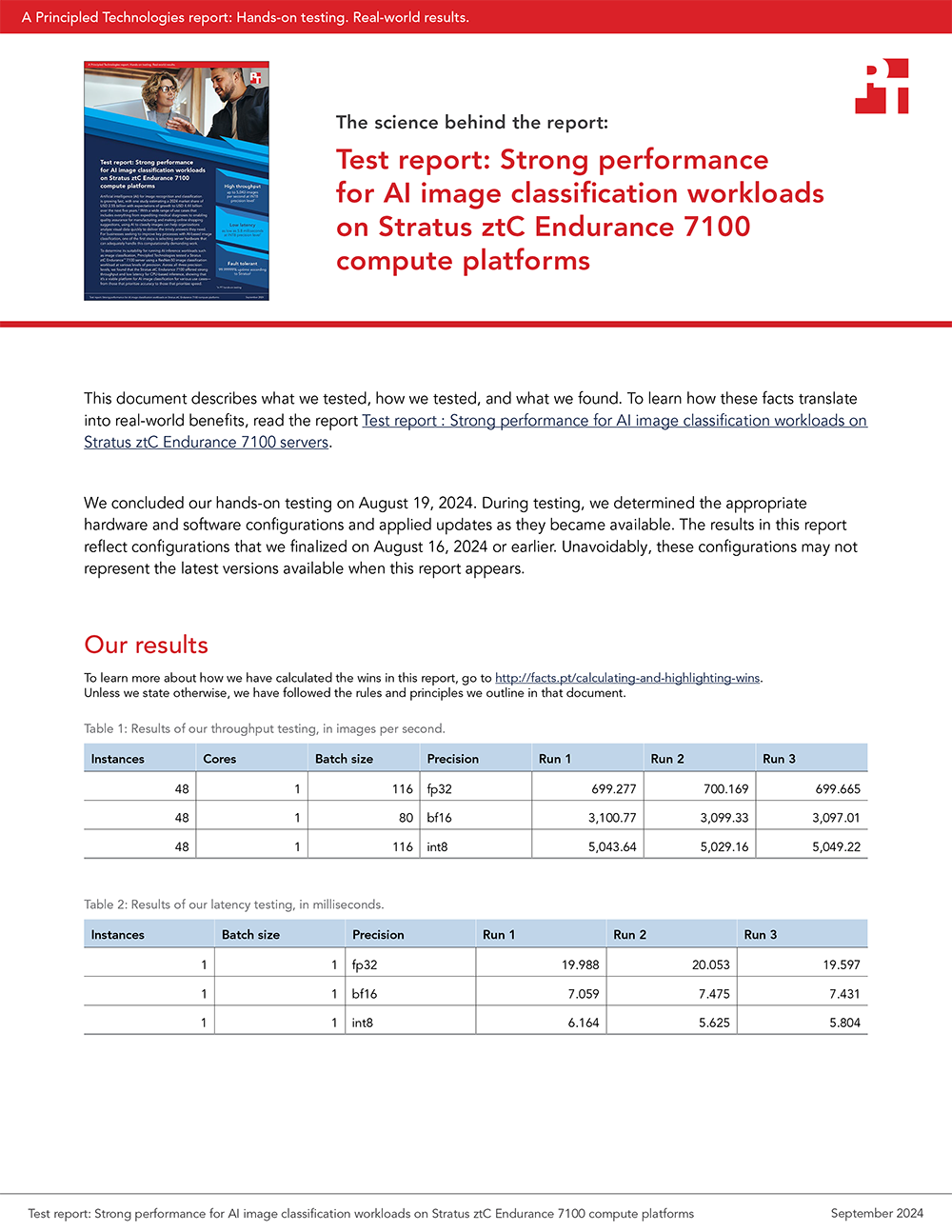
ResNet-50 is a convolutional neural network that runs 50 layers deep to quickly perform image classification. Using ResNet-50 models from the TensorFlow framework as well as Intel Reference Models, we ran image classification performance tests at three different precision levels: FP32, bfloat16, and INT8. The benchmark reports throughput in the number of images per second that the system could classify, as well as latency (wait times) during analysis.
Figure 1 shows the throughput that the Stratus ztC Endurance 7100 achieved while running the ResNet-50 image classification workload at three precision levels using TensorFlow’s and Intel Reference Models’ default suggested batch sizes. These throughput numbers indicate that the Stratus ztC Endurance 7100 is a platform capable of supporting AI inference work for image classification workloads. See page 4 to learn more about precision levels and batch sizes.
Figure 2 shows the latency that the Stratus ztC Endurance 7100 achieved while running the ResNet-50 image classification workload at three precision levels, with a batch size of 1. Lower latencies mean quicker image classification, so as expected, the most precise model had the highest latency. Across the three precision levels, the Stratus ztC Endurance 7100 server had acceptable latencies that show its suitability for running AI inference workloads for image classification.
What do precision levels mean?
When you’re running AI workloads, you can choose the level of accuracy, or precision, that you need the computer to return, allowing you to prioritize the speed of results, image classification accuracy, and/or resource utilization.
As a Principled Technologies engineer put it in the AIXPRT benchmark blog, “Higher levels of precision for inference tasks help decrease the number of false positives and false negatives, but they can increase the amount of time, memory bandwidth, and computational power necessary to achieve accurate results. Lower levels of precision typically (but not always) enable the model to process inputs more quickly while using less memory and processing power, but they can allow a degree of inaccuracy that is unacceptable for certain real-world applications.”5
We tested with three different precisions:
- FP32, or single-precision (32-bit) floating point format, offers a high degree of mathematical precision. This is the highest precision format we used in testing, and would provide the level of precision required for use cases such as die inspection on a semiconductor line or medical imaging.
- Bfloat16, or half-precision (16-bit) brain floating point format, uses half the number of bits as FP32 to represent a model’s parameters. It “decreases time to convergence without losing accuracy” and offers the same range as FP32 but uses half of the memory space.6 Use cases for this precision level might include weather forecasting and climate modeling.
- INT8 is the 8-bit integer data type that has a lower precision level than FP32. INT8 precision can significantly improve latency and throughput, but this increase in speed is often (but not always) at the cost of accuracy. Use cases that might use this level of precision include identification of valve settings in a manufacturing plant or cameras recognizing vehicle license plates to match security records.
Adjusting batch sizes for different windows into image classification results
For ResNet-50, batch size refers to the number of images you want the framework to process simultaneously. Smaller batch sizes tend to deliver lower latency, meaning a batch size of 1 “can be a good indicator of how a system handles near-real-time inference demands from client devices.”7 This is why we used a batch size of 1 for measuring latency on the Stratus ztC Endurance 7100.
For our maximum throughput tests, we used larger batch sizes—the model frameworks’ default batch sizes of 116 or 80—because increasing the number of simultaneous images to classify shows another aspect of what a system is capable of when it comes to running inference work.
Conclusion
The use of AI to classify bulk image data is climbing across many types of organizations—from healthcare to transportation to retail—all of which can benefit from strong servers that can derive answers from image data quickly. Our test results show that the Stratus ztC Endurance 7100 offers a platform suitable for running these kinds of AI inference workloads, offering strong throughput and low latency at multiple precision levels running ResNet-50 image classification. This means that whether your organization’s work requires extreme precision (such as in medical imaging) or values speed (such as in online shopping suggestions), the Stratus ztC Endurance 7100 is a strong platform that can meet your AI image classification needs.
Principled Technologies disclaimer

Principled Technologies is a registered trademark of Principled Technologies, Inc.
All other product names are the trademarks of their respective owners.
DISCLAIMER OF WARRANTIES; LIMITATION OF LIABILITY:
Principled Technologies, Inc. has made reasonable efforts to ensure the accuracy and validity of its testing, however, Principled Technologies, Inc. specifically disclaims any warranty, expressed or implied, relating to the test results and analysis, their accuracy, completeness or quality, including any implied warranty of fitness for any particular purpose. All persons or entities relying on the results of any testing do so at their own risk, and agree that Principled Technologies, Inc., its employees and its subcontractors shall have no liability whatsoever from any claim of loss or damage on account of any alleged error or defect in any testing procedure or result.
In no event shall Principled Technologies, Inc. be liable for indirect, special, incidental, or consequential damages in connection with its testing, even if advised of the possibility of such damages. In no event shall Principled Technologies, Inc.’s liability, including for direct damages, exceed the amounts paid in connection with Principled Technologies, Inc.’s testing. Customer’s sole and exclusive remedies are as set forth herein.






 Twitter
Twitter Facebook
Facebook LinkedIn
LinkedIn Email
Email